
کورس دوم اسپشیالیزیشن ماشین لرنینگ: Advanced Learning Algorithms
فهرست مندرجات
هفتهٔ اول
- نورال نتورک هدفش میمیککردن رفتار مغز انسانه و دههها پیش ابداع شده.
- یکی از اولین حوزههایی که نورال نتورک توش موفقیت داشت اسپیچ ریکوگنیشن بود و بعد تصاویر و بعد متون و حالا موضوعات خیلی متنوعی
- در معماری نورال نتورک باید تصمیم بگیریم که چند تا هیدن لیر داشته باشیم و در هر لیر چند تا نیرون داشته باشیم.
- جذابیت نورال نتورک اینه که خودش فیچرهای layerها رو میفهمه. لازم نیست ما براش تعریف کنیم تو هر لایه دنبال چه فیچرهایی تو خروجی هستیم.
- شماره layer رو همیشه در [1] سوپراسکریپت و شماره نورون یا یونیت در هر layer رو در سابسکریپت مینویسیم.
- اسم این اکتیویشن فانکشن معمول g همون سیگمویده که خروجیش میشه اکتیویشن ولیو یا خروجیهای یک لایه.
- تنسورفلوی ۲ بهش کراس هم اضافه شده.
- وقتی اکتیویشن نداشته باشیم میشه مدل linear یا خطی.
هفتهٔ دوم
کورس ریکامندرسیستمهای ادونس: Advanced Recommender Systems
هفتهٔ اول
هفته اول: استفاده از ML در ساخت ریکامندر سیستم + اوورفیتینگ + نرمالیزیشن و رگولاریزیشن برای جلوگیری از اوورفیتینگ + ارزیابی از روی pairwise
فرض کن دو تا ماتریس داریم با ضرب این دو تا میرسیم به ماتریس سوم که سطرهای ماتریس سوم یوزرها و ستون هاش آیتمها و خانههای پردیکشن هر یوزر به هر آیتمه. ماتریس اول ضرب ماتریس rating واقعی هر یوزر به هر آیتمه. ماتریس دوم شباهت آیتم با آیتمه. پس سطر i از ماتریس اول میشه rating یوزر i به همه item ها و ستون j از ماتریس دوم میشه شباهت آیتم j با همه آیتمهای دیگر. این دو را در هم ضرب نقطهای کنیم میشود پردیکشن یوزر i به آیتم j. براساس معیار شباهت میشه گفت که پردیکشن فانکشنی از معیار شباهت بوده. بعد میشه ماتریس پردیکشن را با ماتریس واقعی ریتینگ مقایسه کرد و پرسیژن و ریکال و اکوریسی یا auc یا mae و mse حساب کرد. میشود با استفاده از ماشین لرنینگ فهمید که از چه سیمیلاریتی مدلی استفاده کنیم بهتره. این یک مسئله اوپتیمایزیشن بزرگه. چند تا سیمیلاریتی مژر داریم و برای هر کدام باید ارور را بین پردیکشن و ریتینگ حساب کنیم و تعداد سیمیلاریتی زیاده پس ترینش خیلی سنگینه.
اگر ماتریس سیمیلاریتی رو برابر ماتریس دیاگونال I بگیریم یعنی هر کسی با خودش ۱ شباهت داره با بقیه صفر اونوقت R - RS میشه صفر یعنی ارور میشه صفر که به این میگیم اوورفیتینگ برای حل مشکل اورفیتینگ دو تا کار میکنیم: ۱- قطر S را صفر میگذاریم. ۲- رگولاریزیشن میکنیم. یعنی یه مقدار لامبدا ضربدر نرم S به ارورمون اضافه میکنیم. به لامبدا میگیم لاس فانکشن و مقدار مناسبش رو باید با tune کردن به دست بیاریم. در اینجا فرض شده که ماتریس سیمیلاریتی sparse هست.
میشه به جای MSE سعی کرد pairwise ranking ها رو optimize کرد. اینجوری که احتمال اینکه برای هر یوزر u مقدار ریتینگ پیشبینی شده برای آیتم i بیشتر از مقدار پیشبینی شده برای آیتم j باشه اگر i را از بین مواردی که کاربر rate داده انتخاب و j را از آنهایی که rate نداده انتخاب کرده باشیم.
هفتهٔ دوم
هفته دوم: ماتریکس فکتوریزیشن و دایمنشنالیتی ریداکشن با تکنیک Singular Value Decomposition + فرق memory-based و model-based + پارامتر number of latent features
فرض کنین که آیتمها یه سری فیچرهایی دارن که نمیدونیم چیه. میدونیم یوزرها هم چه نظری نسبت به این فیچرها دارن. بر این اساس ریکامند میکنیم. شبیه کانتنت بیسد میشد با این تفاوت که در کانتنت بیسد میدونیم فیچرهای هر آیتم چیه. اینجا نداریم.
ماتریس اول سطرهاش یوزرها و ستونهاش فیچرها باشند. نظر هر یوزر نسبت به تمام فیچرها مشخص شده. ماتریس دوم سطرهایش فیچرها و ستونهایش آیتمها باشد. حاصل ضرب این دو ماتریس به ما ماتریس پردیکشن را میدهد. اینطوری که یک وکتور داریم از نظر یوزر نسبت به k تا فیچر. یک وکتور هم داریم از میزان نزدیکی هر آیتم به k تا فیچر که این دو ضرب نقطهای میشود.
در کانتنت بیسد میگیم اتریبیوت مثل ژانر و … ولی در این روش میگیم فیچر چون یه چیز ابسترکت ریاضیه. تعداد فیچرها بین ۱۰ تا ۲۰۰ هست و بستگی به دیتا داره: ۱- اگر تعداد فیچرها زیاد بگیریم و rating ها کم باشد خطر اورفیتینگ دارد و پرفرمنسش کم میشود. ۲- اگر تعداد فیچرها کم بگیریم و rating زیاد باشد میزان personalization کم میشود و بیشتر most popular ها را ریکامند میکند و بایاس دارد.
اینجا هم رگولاریزیشن ترم اضافه میکنیم تا ماتریس ها را اسپارس کنیم و لامبدا ۱ و لامبدا ۲ باید تیون شوند. نباید خیلی بزرگ باشد تا ماتریس ها خالی نشود. دو تا فرض میشه داشت: ۱- فرض missing as random میگه که مواردی که امتیاز نداده را صفر بگیر. این میتونه با دقت خوبی rate ها رو پیشبینی کنه. ولی naive هست چون فرض کرده توزیع صفر ها با اونایی که rate داده یکیه. در funk svd از این استفاده میشه. ۲- فرض missing as negative میگه مواردی که امتیاز نداده را منفی بگیر یعنی کاربر احتمالا چیزی که rate نداده را احتمال بیشتر ازش خوشش نمیاد. این برای پرسیژن و ریکال بهتر جواب میده. در baysian personalized ranking از این استفاده میشه.
روش funksvd اینجوریه که اول تعداد فیچرها رو یک در نظر میگیریم و میگیم ماتریس اصلی حاصل ضرب ماتریس یوزر و فیچر و ماتریس فیچر و آیتمه. بعد با روش als یا alternative least square اینطوری کار میکنیم که ماتریس اول را ثابت میگیریم ماتریس دوم را حساب میکنیم بعد ماتریس دوم حساب شده را ثابت میگیریم و ماتریس اول را حساب میکنیم و انقدر ادامه میدهیم تا خیلی تغییر نکنند. بعد یک فیچر به هر دو ماتریس اضافه میکنیم و دوباره als میزنیم تا برسیم به مقدار خوبی از تعداد فیچرها.
در svd++ که نسخه کاملتر funksvd هست میاد به جز بایاس هر یوزر و بایاس هر آیتم که قبلا در funksvd اضافه کرده بودیم یک مقدار بایاس global effect هم به اسم میو اضافه میکنه. چون این مقدار گلوبال اضافه میشه دیگه نمیشه بر خلاف funksvd از als توش استفاده کرد.
هم funksvd و هم svd++ هر دو ایرادشون اینه که مدل بیسد کار نمیکنن یعنی هر بار که یه یوزر جدید به سیستم اضافه شه باید دو تا ماتریس یوزر و فیچر و ماتریس فیچر و آیتم از اول حساب شه و همینطور global effect. برای همین سعی میکنیم که این روش های memory-based را که پرفرمنس داغونی به خاطر train مجدد دارن به model-based تبدیل کنیم. متد asymmetric svd مشکل اضافه شدن یوزر جدید را حل میکند اینطوری که سطر مربوط به امتیاز کاربر جدید به فیچرها را تخمین میزند. برای تخمین زدن اینکه کاربر جدید u به فیچر k چه امتیازی میدهد بردار امتیازهایی که کاربر u به همه آیتمها داده را ضرب نقطهای میکنیم در بردار اینکه هر آیتم چقدر به فیچر k مربوط است.
خود svd متد دیکامپوز کردن یک ماتریکس ریتینگ یوزر به آیتم به حاصلضرب سه تا ماتریکس هست. ماتریس اول که ماتریس یوزره و یک ماتریس مربعیه سطرها یوزرهاست و ستونها فیچرهان. یک ماتریس متعامده یعنی. بعد در نسخهی truncated svd یا pure svd میایم ستونهای آخر ماتریس اول و سطرها و ستونهای ماتریس دوم و سطرهای آخر ماتریس سوم را حذف میکنیم چون اهمیت کمتری دارند و نویز کم میشود.
هفتهٔ سوم
هفته سوم: انواع هایبریدایز کردن
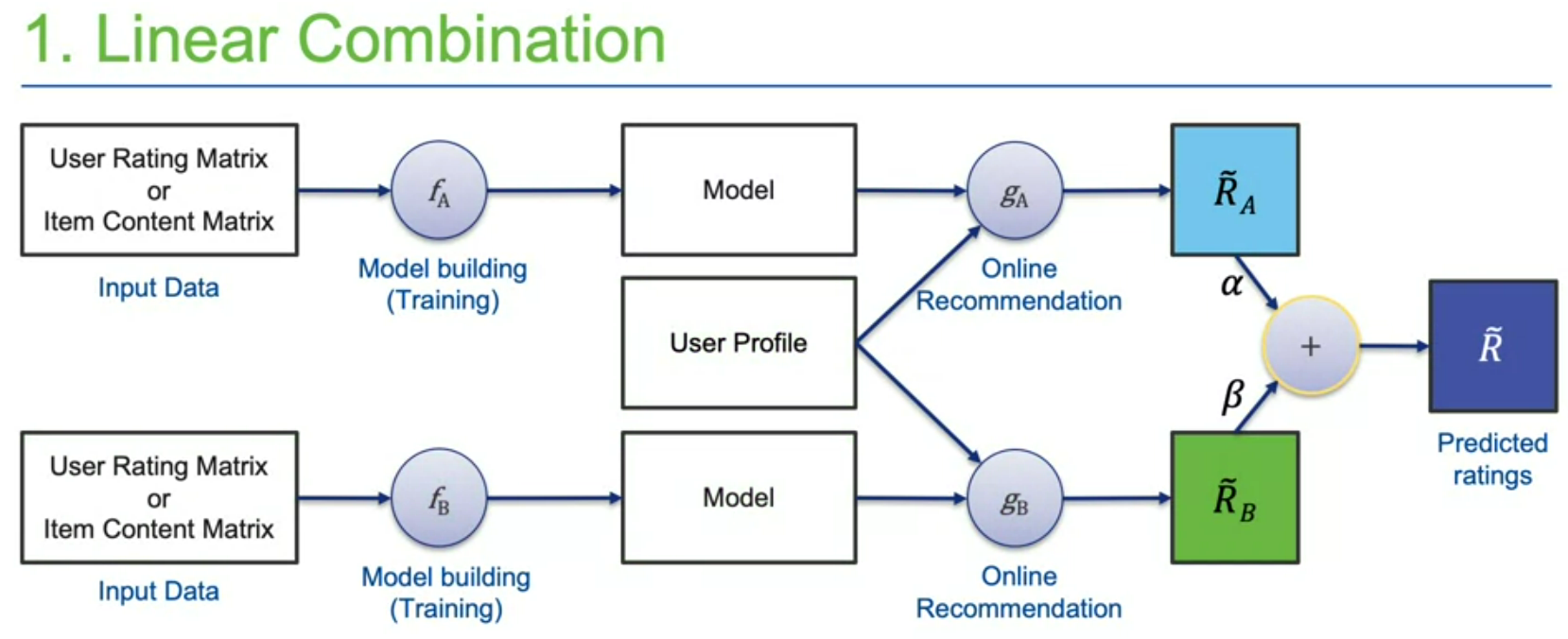
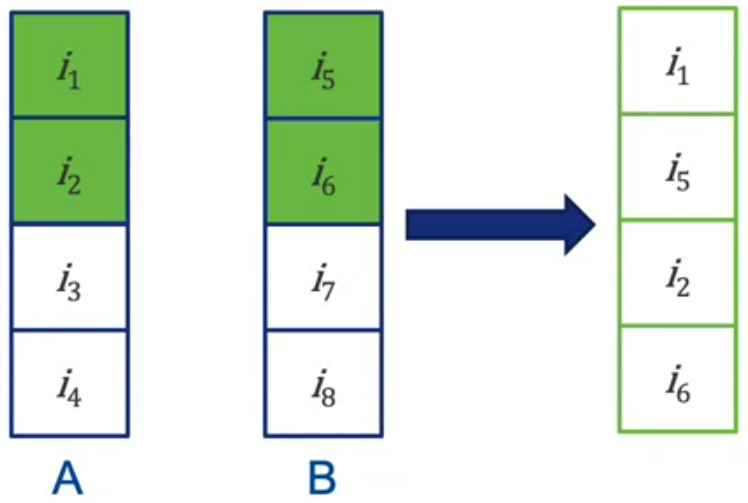
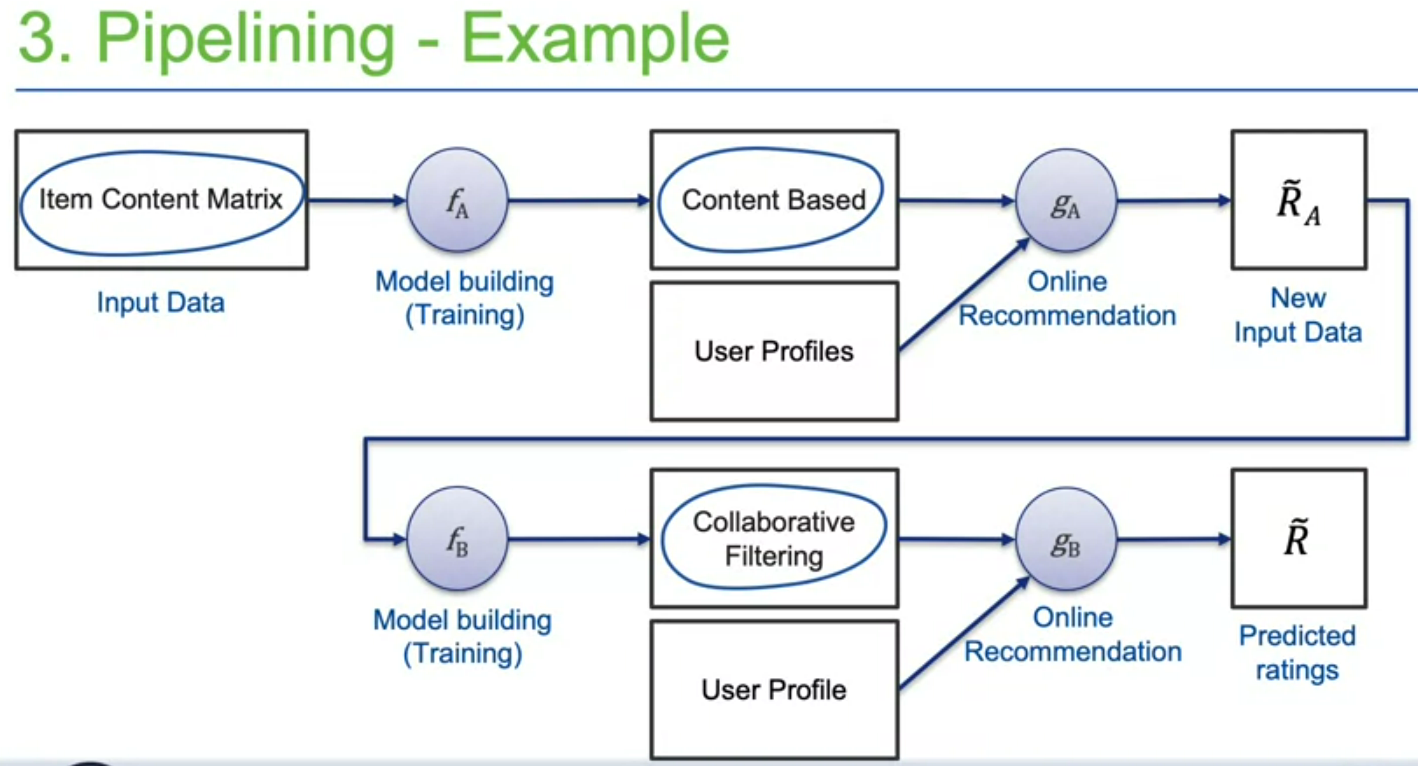

۱- متد اول linear combination هست. بدون هیچ تغییری خروجی هر الگوریتم را به صورت linear و با وزن مشخصی جمع میکنیم. با استفاده از grid search میشه وزنهای مناسب برای هر الگوریتم را تیون کرد. مزیتش سادگیه. ایرادش اینه که وزنها برای هر دیتاست یک مقداری تیون میشه. همینطور باید اسکیل rate ها یکی باشه. ۲- متد دوم list combination هست. لیستهای ریکامندر خروجی را با هم ترکیب میکنیم. مثلا round-robin از بالای هر لیست ریکامندیشن یکی برمیداریم تا top10 کامل شه. مزیتش اینه که نیازی به scale یکسان بین الگوریتمها نداره. ولی اشکالش اینه که وزن اهمیت ریکامندرها را راحت نمیشه مشخص کرد. ۳- متد سوم pipelining هست. خروجی یک الگوریتم رو به عنوان ورودی به یک الگوریتم دیگر میدهیم اینجوری که خروجی الگوریتم اول مثلا کانتنت بیسد یک سری ریتینگ پردیکت میکند. با این پردیکشنها ماتریس rating که از اول داشتیم را کامل میکنیم و میدهیم به الگوریتم ریکامندر دوم مثلا کلبریتیو. ماتریس rating در این روش خیلی dense تر میشود و دیگر sparse نیست ولی پرفرمنسش پایین است.
خانواده دوم هایبریدسازی اینه که side information بدیم مثلا اینریچ کنیم دیتای کلبریتیو فیلترینگ را با دادههای ادیشینال: ۴- متد چهارم merging models است. مدل یک ریکامندر را با مدل یک ریکامندر دیگر ترکیب میکنیم تا یک مدل جدید بسازیم برای ریکامند کردن ولی مدلها باید ساختار مشابهی داشته باشند. مثلا ماتریسهای فاکتورها در matrix factorization را نمیشه با ماتریس سیمیلاریتی collaborative ترکیب کرد. ولی میشه سیمیلاریتی collaborative و content base را با هم linear جمع کرد. مثلا مدل اول item base هست که سیمیلاریتی itemها رو مدل کرده روش دوم content base هست که برحسب کانتنت شباهت item ها رو مدل کرده. دو تا ماتریس شباهت را با هم جمع میزنیم با یک ضرایبی. خود این ضریب را با grid search میشود تیون کرد. مدلها در این روشها باید کامپتیبل باشند مثلا item base را نمیشود با user base ترکیب کرد چون معنیشون فرق داره یکی شباهت یوزرهاست یکی شباهت آیتمها. ۵- متد پنجم co training با side information هست. در فاز train کردن موقع ساخت مدل الگوریتم a و b را با هم استفاده میکنیم. این ایدش اینه که اگر ما کانتنت یک آیتمی را نداریم میتونیم به آیتم شبیهش نگاه کنیم و از طریق اون کانتنتش را تکمیل کنیم. سیستمهای context aware هم context ای که یوزر با آیتم اینترکت کرده رو به عنوان side information لحاظ میکنن. سادهترین روشش tensor factorization هست. tensor ماتریس حداقل سهبعدی هست اینجوری که به ماتریس user item rating یه بعد سوم context اضافه میکنیم و تنسور میسازیم. درواقع کل کانتکست rate ای که داده رو تو یه بعد خلاصه میکنیم. مثلا کاربر روز شنبه این امتیاز را به فیلم داده. تو مرحله فاکتوریزیشن هم به جز ماتریس یوزر و ماتریس آیتم که قبلا داشتیم حالا در یک ماتریس سوم کانتکست هم ضرب میکنیم. اشکالش اینه که ماتریس را اسپارستر میکنه وقتی کانتکست را اضافه کنیم. هر چه متغیرهای کانتکست را کمتر کنیم کمتر پرسونالایزد میشود.
هفتهٔ چهارم
فکتوریزیشن ماشین = از ساید اینفورمیشن استفاده میکنه + تکنیک های ماشین لرنینگ برای کتگوری بندی بر اساس یک سری پارامترها که ادپتبل به ریکامندر سیستم هست صورتبندی hot encoding برای تبدیل URM به مسئله ماشین لرنینگ اینجوریه که یه جدول داریم که هر سلول URM میشه یک سطرش. اینجوری که هر سطر یک یوزر و یک آیتم را ریپرزنت میکنه و label میشه امتیازی که اون یوزر به اون آیتم داده. اینجوری ماتریس اسپارستر از قبل میشه حتی. چون تو هر سطر به ازای همه یوزرها و همه آیتمها یک عالمه صفر داریم و فقط یک یوزر و یک آیتم یک میخوره و جلوش label که rating هست. برای پیشبینی امتیاز یک سطر از این جدول بایاس گلوبال کلی را با بایاس آیتمی که در این سطر یک خورده با بایایس یوزری که در این سطر یک خورده باید جمع بزنیم. برای اینکار یک امگا که مقدار بایاس برای هر ستون جدول یعنی برای هر یوزر و آیتم هست را با ماشین لرنینگ پیدا میکنیم. حالا باید رابطه بین فیچرها را برای پیشبینی امتیاز لحاظ کنیم و جمع بزنیم. برای اینکار یک ماتریس وزن برای یوزر و آیتم داریم که وزن مربوط برای یوزر و آیتمی که در این سطر خاص یک خوردند را از آن درآورده و جمع میزنیم. این ماتریس وزن یوزر و آیتم خیلی بزرگ و اسپارس هست برای همین خود این ماتریس را هم رویش ماتریکس فاکتوریزیشن میزنیم که کوچکتر شود. یعنی تو دل فاکتوریزیشن ماشین یک ماتریکس فاکتوریزیشن انجام میدهیم. مزیت فاکتوریزیشن ماشین نسبت به collaborative filtering سنتی این است که فکسیبل هست تو استفاده از سورسهای بیشتر دیتا. مثلا میشود اطلاعات کانتکست یا اطلاعات side information درباره یوزر یا درباره آیتم را هم در ادامه ستونهای جدول اضافه کرد بدون تغییر دادن فرمول و اینجوری خود مدل را هایبرید کرد. همینطور میشود به جای گذاشتن یک در یکی از ستونهای مربوط به یوزر در یک سطر خاص عدد مثلا دو یا نیم گذاشت که اهمیت وزن خصوصیات آن یوزر را کم یا زیاد کرد. ددر ایمپلیسیت ریتینگ ما امتیاز dislike یا 0 نداریم فقط یک سری ۱ داریم و این مشکل imbalance در فاکتوریزیشن ماشین ایجاد میکند یعنی اشکالش اینه که الگوریتم لرن میکنه به همه ۱ بده. برای حل این مشکل میایم از اونایی که امتیاز نداده رندم یک سریشون رو صفر میکنیم. اشکالش اینه که نمیدونیم اینکه صفر کردیم رو ندیده یا دیده خوشش نیمده و اگر ندیده شاید ریکامندیشن خوبی باشه اتفاقا ولی اشکال نداره چون تعداد کل آیتمها خیلی زیاده و به طور کلی میدانیم احتمال خوش اومدن کاربر از یک آیتم کمه.
کورس اول اسپشیالیزیشن ریکامندر سیستم
وقتی چندین چویس داریم و از بین اینا باید انتخاب کنیم و نمیونیم اطلاعات مورد نیاز رو پیدا کنییم. مورچه هایی که وقتی فضا رو کشف کردن به همدیگه اطلاع میدن. غارنشینها آیا این غذا رو خوبه بخورم یا این فیلم رو ببینیم؟ یا این کالا رو بخرم؟ این آهنگ رو گوش بدم؟ این خبر رو بخونم؟ با این آدم دوست شم؟ گوگلم ریکامندره چون یه چیزی بهش میگی بعد میگه این صفحات رو احتمالا خوشت میاد.
اینتفورمیشن ریتریوال → دیتاستهای استاتیک که زیاد آپدیت نمیشن یا تغییر نمیکنن ولی کوئری زیاد داریم → مثال کاتالوگ کردن کتابها برحسب نویسنده یا برحسب موضوع. وب. تیاف آیدیاف → تو این داکیومنت هر کلمه چقدر اومده. این کلمه در کل چقدر اومده برای رنک کردن نتایج.
اینتفورمیشن فیلترینگ → دیتاستهای پویا که استریم دیتان مثه اخبار ولی کوئری من ثابته مثلا اخباری که اسم منو دارن. کلبوریتیو فیلترینگ → اگر کسی اینو قبلا برای من دیده نیاز نیست منم ببینم.
نوآوری: نگتیو فیدبک پروژهها یعنی اون کتابخانه هایی که پاک کردن رو هم در نظر بگیریم. یا تو فیدبک لوپ کاربر بگه این کتابخانه به دردم نمیخوره دیگه نشونم نده و اینم در نظر بگیریم. شکلی که توضیح میده فیدبک رو هم برمیگردونیم به دیتابیس برای استفادههای بعدی. انواع اینترفیسهای ریکامندرها. نوآوری: کنار هر چیزی که ریکامند میکنیم بگیم چرا اینو ریکامند کردیم. مثلا براساس شباهت با فلان پروژه یا چون اینا رو استفاده کرده بودی. نوآوری: کاربر بتونه الگوریتم ریکامندیشن رو خودش انتخاب کنه. یه سری کاستومایزیشن هم تو یوزر اینترفیس بذاریم مثلا اینکه نمیخواد خیلی پاپیولارها رو بهش ریکامند کنیم. کلا تو اینترفیس میتونیم تمام پارامترهای فیلتر کردن نتایج رو شبیه دیتا استودیو نشون بدیم به کاربر.
اکلسپیلیسیت → کاربر مستقیم چیزی رو لایک یا دیسلایک کرده یا به فیلم امتیاز داده یا نظرش رو نوشته. از خودش بپرس. ایمپلیسیت → نگفته چیو ترجیح میدم ولی از کاری که کاربر انجام میده میشه استخراج کرد. مثلا به دیدن یه فیلم ادامه ندادم. یه لینکی رو روش کلیک کردم. چیزی رو خریدم. کسی رو فالو کردم. از کتابخونه استفاده کردم. نوآوری: ایمپیلیسیت برای انتخاب تکنولوژی چیا دیگه داریم؟ مثلا چه مقدار یا چه مدت از کتابخونه استفاده میکرده؟
انواع پیشنهاد: - پرسونالایزنشده → فلان چیز پاپیولاره - یا مربوط به یه گروهه نه شخص مثلا مردهای بین ۲۰ تا ۳۰ ساله کرهای - پروداکت اسوسیشن → اگه این پروداکت رو خریدی احتمالا اینم میخری و پرسونالایزد نیست - کانتنت بیس → نگاه میکنیم به محتوای پروفایل شما پیشنهاد میدیم. نوآوری: ساخت یک پروفایل برای کاربر شامل پایچارت چند درصد از کتابخانههایی که استفاده کردی common و چند درصد rare هست. از هر حوزه چند تا کتابخانه استفاده کردی یا زبان اصلیشون چی بوده به صورت بارچارت. - کلبوریتیو
روشهای جدید ریکامند از متدهای جدید ماشین لرنینگ هم استفاده میکنن.
نوآوری: مشکل cold start داریم. اینو چطوری حل کنیم؟
فرق ریکامندیشن و پردیکشن. خوبی ریکامندیشن اینه که با دیفالت گزینه های خوب رو نشون میده ولی اگر صفحه اول پیدا نشد دیگه بقیش رو نمیبینه. خوبی پردیکشن اینه که میگه چقدر برامون ارشمنده ولی ممکنه اشتباه باشه.
نحوه ریپرزنت کردن ریکامندیشن میتونه اکسپیلیسیت باشه عین فروشنده ای که وارد مغازه میشی میخواد push کنه که چیزی رو بخری یا تو سایت بنویسی ریکامندیشن مخصوص شما میتونه اورگانیک باشه. مثلا طبقه کتاب های پرفروش تو کتاب فروشی ها. یا اینکه آهنگ پیشنهادی بعدی خودش پخش شه نه اینکه هی سوال کنه و اینترکشن بخواد. → بالانس بین این دو تا things you might like
چیزهایی رو پیشنهاد کنیم که قبلا ندیده مثل فیلم یا کتاب یا چیزایی که قدیم دیده و حالا ممکنه بازم بخواد مثل آهنگ یا میوه
هدف ریکامندرها خیلی وقتا فروشه خیلی وقتا اینفورمیشن دادن به کاربر. مثال: سیستمی که آپشنهای ورد که کاربر استفاده نمیکنه ولی به کارش میاد رو بهش توضیح و آموزش میده. نوآوری: برای ما اینفورمیشنه پس چه بهتر که فقط کتابخونه پیشنهاد ندیم یه اطلاعاتی درباره کتابخونه رو همونجا نشون بدیم تا کاربر یاد بگیره. موفقیت آموزش کاربره.
نوآوری: از رو شباهت استارهای کاربرها بیایم کتابخونه بهشون پیشنهاد کنیم. یعنی کاربر به جای ریپازیتوری خود فرد باشه و آیتم پروژههای لایک شده. نوآوری: از رو شباهت کتابخانههای یک کاربر در پروژههای مختلفی که زده بهش پیشنهاد کنیم. آیتم ینی کتابخانههای پروژههای فرد باشه.
ریکامندر برحسب صرفا opinion ها هست. حالا این opinion مال کیه؟ ما داریم از دادهی افراد اکسپرت استفاده میکنیم یا افرادی مثل خودت؟ نوآوری: ریپازیتوریهای استار بالا تو train بیاد چون ما اکسپرت نیستیم و میخوایم اکسپرتهای حوزه به ما ریکامند کنن نه افراد معمولی مثه خودمون. برای اینکه trustworthy باشه توصیه ها باید کالایی رو توصیه کنیم که موجود داریم. نوآوری: کتابخانههایی رو پیشنهاد کنیم که میشه ازش استفاده بکنه کامپتیبله یا مثلا لایسنسش رایگانه یا دیپریکیت نشده یا یه حداقل تعداد star ای داره.
نتیجه بایاسد: افرادی که هفتههای اول میرن یه فیلم رو میبینن اونایین که دوستش دارن پس فیلم های جدید امتیاز بالاتر میگیرن. پس به نتایج روزهای اول خیلی دقت نکنیم.
کانتنت بیسد فیلترینگ: میگه بیایم اتریبیوت های آیتم ها رو هم در نظر بگیریم و بگیم در مجموع به مثلا هر ژانر فیلم چه امتیازی داده. نوآوری: کتابخانههای ما مثلا دومین دارن. بگیم از کتابخونه هایی خوشش میاد که مال این دومینن. یا کتابخانه های پایدارتر رو بیشتر دوست داره از جدیدترا.
کانتکست پیشنهادی که میدیم مهمه. برای اینکه پیشنهاد بیربط ندیم مثلا کچاپ برای سس بستنی رو پیشنهاد ندیم چون محبوبه نوآوری: (مهم) نگاه کنیم که بقیه پروژه هایی که مال دومین ما هستن تو گیتهاب از چه کتابخونه هایی استفاده کردن و از بین اونا فقط مجازیم که بهش پیشنهاد کنیم.
نوآوری: یه پارامتر بدیم دست کاربر که بتونه انتخاب کنه که چقدر میخوایم ریکامندیشن هامون بدیهی نباشه و خلاقانه باشه ولی در عوض ریسک اینکه چیز درستی ریکامند نشه بره بالا. یعنی حد تحمل ریسک یا کانسرویتیو بودن کجاست.
نوآوری: (مهم) idf رو در نظر بگیریم یعنی اگر کتابخانه در تعداد پروژههای کمتری به کار رفته باشه یعنی بهتره ریکامندش کنیم چون مرتبط تره به پروژهی ما.
نان پرسونالایزد هم سریعه هم کلد استارت نداره.
نوآوری: (مهم) ویکلی پرسونالایزد میتونه باشه یعنی برحسب گروهی از کاربرها داده rating رو جمع کنیم و پیشنهاد بدیم. مثلا بگیم پروژه های این دومین چطوری rate دادن بر اون اساس پیشنهاد بدیم.
نوآوری: (مهم) پروژههایی که جدید اومدن هنوز خیلی کسی فرصت نکرده ازشون استفاده کنه. مدتی که پروژه اومده رو هم در کنار پاپیولاریتی و اینا میشه لحاظ کرد
نوآوری: (مهم) میشه تو هر دومین گفت چیا most popular هستن. بعد به دومین کاربر هم توجه کنیم تو ریکامند دادن. این میشه دموگرافیک.
نوآوری: بحث اینکه چقدر تخصص لازمه برای استفاده از این کتابخونه. مثل کتاب که چک میکنیم مناسب کدوم گروه سنیه.
نوآوری: اول از همه tag ها و بعد review ها برای تولید اتریبیوت های هر کتابخانه برای کانتنت بیس مناسبه. خب برای تگ یکی از نسورسها میتونه تگ های استک اوورفلو باشه که همراه تگ یه کتابخونه به کار رفته. برای review ولی کار سخته باید سنتیمنت و اینا دربیاریم از رو متن استک اوورفلو. نوآوری: متادیتای کتابخونه برای کانتنت بیسد چیا داریم؟
یه روش هایبرید استفاده کنیم. یعنی ترکیبی از کانتنت بیسد و …
کورس دوم اسپشیالیزیشن ریکامندر سیستم
نوآوری: میتونیم وقتی میخوایم امتیاز همه کاربرهای نزدیک رو جمع بزنیم امتیاز هر کاربر رو منهای میانگین کل امتیازهایی که داده کنیم. اینجوری کاربری که کلا کم امتیاز میده ینی کتابخانه های کمتری استفاده میکنه در شرایطی که یک اندازه شبیه باشه به ما، امتیازش اسکیل میشه میاد تو بازه پروژههایی که کتابخانههای بیشتری استفاده کردن.
پیرسون خیلی برای شرایطی که تعداد آیتمهای مشترک میتونه کم باشه مناسب نیست کلا. مثلا دو تا یوزر از دو تا آیتم مشترک استفاده کردن کورلیشن پیرسون احتمالا یک میشه ولی نمیشه گفت شبیهن. برای unary هم مناسب نیست.
کلا کلبریتیو فیلترینگ روی این فرضیه بنا شده که سلیقه آدما ثابته و تغییر نمیکنه بعدا. پس اگر قبلا با هم موافق بودیم بعدا هم موافق خواهیم بود. دوما آدمایی که شبیه شما هستن باید تو یه دومین مشخص باشن. افرادی که در مورد فیلم سلیقه مشابه دارن در مورد مجله لزوما مشابه نیستن.
نوآوری: بیایم دومین بیس مدلهای جدا بسازیم.
میتونه فقط بحث اینکه کی شبیه منه نباشه بحث اینکه من به کی trust دارم هم باشه.
پیدا کردن bad rating و ignore کردن آن سخت تره از پیدا کردن bad rater و ignore کردن آنها. به وسیله پیدا کردن signature این rater ها. مثلا اینکه چقدر وقت گذشته از وقتی اکانت رو ساخته و …
تراستبیسد ینی نگاه کنیم کاربر به چه افرادی تراست داره و از اون به عنوان وزن استفاده کنیم نه سیمیلیاریتی. تو سوشیال نتورکها کاربرد داره از روی ارتباط آدما با هم میشه تراستشون رو مشخص کرد. تراست با ریپوتیشن جنرال آدما فرق داره.
تو آیتمآیتم میگیم این آیتمها شبیه آیتمهایین که شما دوست داشتی. ینی neighbour رو برای item ها پیدا میکنیم. تو آیتمآیتم وقتی میخوایم امتیاز u به i رو پیشبینی کنیم میایم k تا آیتم نزدیک به i که u بهشون امتیاز داده رو پیدا میکنیم. تو محاسبه شباهت بین item ها مواردی که miss کردیم رو باهاشون مثل صفر برخورد میکنیم.
درواقع آیتمآیتم حالت پروداکت اسوسیشن داره. به یوزر میگه برای این پروداکتی که انتخاب کردی اینا بهش شبیهن.
آیتمآیتم معمولا پرفرمنس بهتری داره چون معمولا تعداد یوزرها بیشتره از آیتمها. خوبی دیگش اینه که اگر با topN فقط کار داریم کافیه چند تا همسایه خیلی نزدیک رو برای هر item پیدا کنیم و اینکه item item استیبل تره و خیلی تغییر نمیکنه پس میشه مثلا گذاشت شب شباهت بین itemها رو پردازش کنه و مدل شباهت بین آیتمها رو بسازه. بعد وقتی کاربر پیشنهاد میخواد دیگه اون پردازش شباهت همسایهها دوباره انجام نمیشه ولی تو یوزریوزر باید هر بار شباهت یوزر جدید با تمام یوزرها رو پیدا کنیم. اشکال item item اینه که نمیتونه موارد خیلی سورپرایزینگ رو پیدا کنه و سرندیپیتی کمتری داره. پیشنهادهای بدیهی میده. ما میدونیم این اشیا شبیه اشیاعین که من خریدم این چیز جدیدی نیست. البته در عمل تو آمازون خوب جواب داده ولی تو MovieLens نه چونکه پیشنهادهاش به قدر کافی bold نبودن.
نوآوری: آیتمآیتم مزیت های زیادی نسبت به یوزریوزر داره. اینم پیادهسازی کنیم.
نوآوری: اگر بیایم علاوه بر topN بیایم روی امتیاز prediction هم محدودیت بذاریم و زیر یه عددی رو گزارش نکنیم قطعا پرسیژن و ریکال ارتقا باید پیدا کنه. خودمون رو مجبور نکنیم که حتما ده تا رو باید پیشنهاد بدیم. شاید اصلا یه پروژه ده تا کتابخونه نخواست.
در مورد امتیازهای unary بی معنیه اینکه بگیم میانگین وزندار امتیازی که کاربر به بقیه آیتمها داده و شباهت اون آیتم با بقیه آیتمها رو میگیریم چون اگر کاربر بهشون صفر داده باشه وزن شباهت در امتیاز صفر میشه صفر. و حاصل کل میانگین همیشه یک میشه. پس در این مورد باید شباهت ایتم با همسایههایی که من بهشون امتیاز دادم رو جمع بزنیم صرفا.
برای آیتمآیتم به راحتی میشه روشهای هایبرید داد. مثلا یکی از این روشهای هایبرید trust aware collaborative filtering هست که میاد میزان تراست ما به هر یوزر رو هم داخل فرمول دخیل میکنه.
نوآوری: روش هایبریدی بدیم که تراست aware باشه و میزان تراست میتونه برحسب استار و … ریپازیتوریها مشخص شه.
آیتمآیتم بیسد کاری به این نداره که سیمیلاریتی بین آیتمها رو چطوری مشخص میکنیم. ممکنه این سیمیلاریتی با یه روش کانتنت بیسد مشخص شه.
نوآوری: تو آیتمبیسد از روش کانتنت بیسد سیمیلاریتی مشخص کنیم.
تو یه سیستم ریکامندر رستوران تو فاز پیدا کردن سیمیلاریتی بین آیتمها ما نمیتونیم فاصله کاربر با رستوران رو در نظر بگیریم. ولی میتونیم تو فاز پردیکشن میتونیم دوباره وزندهی کنیم و تنها معیارمون برای وزن دادن میزان شباهت نباشه و اینجا فاصله کاربر رو هم در نظر بگیریم.
نوآوری: تو سیستم ما چه چیزایی رو میشه برای وزن دادن به جز سیمیلاریتی در نظر گرفت؟
مشکلات cold start و راهحلها: ۱- کاربر جدید آمده: برحسب اطلاعات دموگرافیک کاربر بهش پیشنهاد بدیم یا most popular ها رو پیشنهاد بدیم یا explicit ازش چند تا سوال بپرسیم. ۲- آیتم جدید اومده: کانتنت بیس پیشنهادش کنیم به بقیه. رندم به چند نفر که تحمل بالایی دارن و سیستم رو ترک نمیکنن یا به افرادی که دنبال چیزای متفاوتترن پیشنهاد بدیم که فیدبک بگیریم و به افرادی که به چیزای دیگه هم زیاد ریت دادن که ریتی که میدن به این به درد بخوره. ۳- سیستم کاملا جدید: از دیتاست یه سیستمی که قبلا کار میکرده استفاده کنیم. ۴-
کورس سوم اسپشیالیزیشن ریکامندر سیستم: ارزیابی و evaluation
اینکه توی هر شاپینگ کارتی بنویسیم موز و نون بخر فایده نداره چون اول و آخر همه میخرن با اینکه accuracy بالاست. نکته خاصی نداره که چیزی که اول و آخر همه میخرن رو بهشون بگیم بخر. پس متریکی که برای ارزیابی ریکامندر استفاده میشه باید با هدف ریکامندیشن همخوانی داشته باشه.
نوآوری: تو سیستم ما هم اینکه کتابخانههایی که در هر صورت آلردی کاربر میخواست استفاده کنه رو بهش پیشنهاد کنیم خاصیتی نداره. نمیشه موفقیت سیستم رو فقط بر این اساس اندازه گرفت که آیا کاربر واقعا از این کتابخانه استفاده کرد یا نه.
میشه رترواسپکتیو برگشت از دادهی rate هایی که قبلا دادن استفاده کرد برای ارزیابی میشه لایو دیتا جمع کرد و آزمایش کرد.
نوآوری: ما میتونیم کتابخانههایی که با هم تو تکهکدهای داخل stackoverflow ایمپورت شدن رو استخراج کنیم و از این استفاده کنیم برای استخراج association rule
میشه در مواردی که یه الگوریتم خروجی تولید نمیکنه از یه الگوریتم دیفالت استفاده کنیم.
اشکال اندازه گیری MAE یا RMSE اینه که ممکنه پنجاه تای اول رو داریم خوب پیشنهاد میدیم ولی در کل ارور زیادی داریم و برای ما همون پنجاه تا مهمه.
معیارهای ارزیابی مثل MAE یا RMSE رو میشه برای هر یوزر جدا حساب کرد میانگین گرفت اونوقت میگه که به طور میانگین یه یوزر چقدر ارور میبینه. میشه برای کلشون با هم حساب کرد.
متریک receiver operating characteristic curve یا ROC میگه که اگر چند تا پیشنهاد بد بدم به ازاش چند تا پیشنهاد خوب خواهم داد و این رو برای کاتآفهای مختلف رسم میکنه. این متریک برای کلسیفایرهای باینری خوب کار میکنه. مساحت زیر نمودار هرچقدر یبشتر باشه بهتره. کاربردش بیشتر جاییه که میخوایم N را تیون کنیم روی عدد مناسبش.
نوآوری: داده ما هم باینری هست و کاملا معنی میده در مورد کار ما. پس نمودار ROC را هم اضافه کنم.
توی ریکامندیشن اگر پردیکشن به اندازه ای درست باشه که به درستی بگه bad هست خوبه ولی اگر به قدری پردیکشن درست نباشه که بیاد تو ریکامندیشن بده. پس تو دیسیژن ساپورت ارور مهم نیست و فقط top of the list مهمه برامون.
اف وان یه جور میانگین بین پرسیژن و ریکاله.
رسیپورال رنک میاد سیگما میگیره روی یک تقسیم بر جایگاهی که اولین مرتبط رو پیشنهاد دادیم تقسیم بر تعداد یوزرها. پنالتی اینکه پایین تر بیاد تو لیست هی کم میشه.
نوآوری: رسیپال رنک هم کاملا به مسئله ما میخوره و میشه حساب کنیم. مقالات قبلی هم حساب نکردن.
اوریج پرسیژن MAP اینجوریه که از ابتدای لیست تا هر مورد درست پرسیژن رو حساب میکنیم و میانگین میگیریم. اینجوری به جایگاه درست بودن هم دقت کردیم.
نوآوری: معیار MAP برای دادههای باینری معنی میده و اتفاقا در کیس ما هم کاملا کاربردیه. مقالات قبلی هم حساب نکردن.
پیرسون میاد اوردر رنکینگ ما رو با اوردر رنکینگ درست بینشون pearson correleation حساب میکنه اشکالی ولی اینه که فرقی نداره رنکها چقدر اشتباه باشن. اگر بیایم تاکید بیشتری بذاریم روی رنک های بالا میشه nDCG. Discounted Cummulative Gain که میاد رنک های پایین رو تخفیف میده اینجوری که تقسیم میکنه هر رنک رو به لوگاریتم جایگاهش. فقط اولین پیشنهاد رو تقسیم به یک میکنه چون لگاریتم یک میشه صفر و نمیشه تقسیم به صفر کرد.
روش ما برای ارزیابی همش مبتنی بر اینه که چقدر خوب میتونیم بخشی از انتخابهای گذشتهی کاربر رو قایم کنیم و بعد ریکاور کنیم. درحالیکه کاربر انتخابهایی که انجام داده رو یعنی میدونسته و انتخاب میکرد به هر حال اگر چیزی هم ریکامند نکرده بودیم چون آلردی این انتخاب ها رو کرده. کار ریکامندر اینه که یه چیزای بهتری از اون پیشنهاد کنه که کاربر به عقلش نمیرسید. ریکامندر از این منظر با ماشین لرنینگ فرق داره. حتی موقع ارزیابی وقتی پرسیژن ریکال حساب میکنیم میگیم مواردی که انتخاب نکرده رو نباید سیستم پیشنهاد کنه اگر پیشنهاد کرد پرسیژن نداره درحالیکه اتفاقا پیشنهاد خوب از بین اوناست و ما داریم با اینکار سیستم رو به خاطر دادن پیشنهادهای خوب penalize میکنیم.
از طرفی اشکال دیگه این روش ارزیابی اینه که فرض میکنه که ریکامندیشنهای ما تاثیری تو انتخابهای بعدی کاربر ندارن یعنی به هر حال کاربر اونهایی که انتخاب کرده رو انتخاب میکرد درحالیکه اگر کاربر میدونه که چه چیزایی بهترین انتخابها هستن و در هر صورت اونا رو انتخاب میکرد پس چرا اصلا ریکامندیشن میدیم؟ روش درست اینه که در عمل ببریم تست کنیم ولی اینکارو نمیکنیم چون هزینش خیلی زیاده. میگفت ما یه بار اینجوری آزمایش کردیم سیستم MovieLens که فیلم پیشنهاد میده رو. به هر کسی یه فیلمی پیشنهاد میکرد بعد بلیط دیدن اون فیلم رو رایگان به طرف میدادیم چون قرار بود وقت بذاره و فیلمی که ما انتخاب کردیم رو بره ببینه. ولی بخوای به هر کسی پول بدی که بره فیلمی که انتخاب کردی رو ببینه و بعد بگه که انتخاب میکنه یا نه. پس بهتره با روشهای فعلی الگوریتم های بهتر رو پیدا کنیم و بعد اونایی که کاندید خوبین رو ببریم تست کنیم تو شرایط واقعی.
فرض کنید یک سایتی داریم که قیچی ریکامند میکنه و کاربر یه برند خاصی رو دوست داره چون در دسترسش بوده تا الان. حالا ما بیایم یه پیشنهاد خیلی خوبی که نمیشناسه رو بذاریم نتیجه اول و اون رو یه بار استفاده کنه و ازش راضی باشه طوریکه با انتخاب های فعلیش جایگزینش کنه و دیگه اونا رو انتخاب نکنه. در این حالت باید بگیم ریکامندر موفق عمل کرده درحالیکه روش های فعلی ارزیابی اینو penalize میکنن و به اشبا نوآوری: در بخش فیوچر ورک روی این نکته میشه تاکید کرد.
کاوریج درصد تعداد آیتمهایی که سیستم میتواند برای آنها prediction انجام دهد. میانگینش را برای هر بوزر حساب میکنیم. نوآوری: اگر روش هایبرید استفاده کنیم بخشی از itemها که براش نمیشد predict کرد چون دادهی کافی براش نداشتیم رو هم میشه پردیکت کرد.
نوآوری: میشه در ui کنار هر آیتمی که پیشنهاد میدیم یه درجهی confidence هم حساب کنیم و بگیم که چقدر مطمئنیم که این پیشنهاد خوبیه برای شما.
پاپیولاریتی درصد کاربرانی که از آیتمهای پیشنهاد شده استفاده کردند.
نوآوری: بررسی کنیم که در هر بخش دیتاست کتابخانههایی که تو پروژهها استفاده شدن چقدر پاپیولار هستن. مثلا پروژههای خوب چقدر کتابخانههای popular استفاده کردن. طبیعتا کتابخانههای پاپیولارتری استفاده کردن.
نوآوری: بر اساس دادههای پروژهها خوب یکبار train کنیم یک بار هم برحسب دادهی پروژههای ضعیفتر و بعد پیشنهادهایی که برای یه پروژه با این دو تا میده رو مقایسه کنیم که چقدر پاپیولارن و چقدر novelty دارن و …
نوآوری: (مهم) کتابخانههای novel ای که در پروژههای خوب استفاده شدن احتمالا کاندیدهای خیلی خوبین برای پیشنهاد دادن چون هم بدیهی نیستن هم کتابخانهی خوبی بودن که در پروژهی خوبی استفاده شدن. این یعنی همون تابع وزن به پروژههای خوب.
پرسونالیزیشن: میشه بررسی کرد که توی top10 چند تا مورد مشترک برای یوزرها وجود داره. یا محاسبه کرد که واریانس predictionهایی که برای آیتمها به هر یوزر میدهیم چقدره.
نوآوری: پرسونالیزیشن رو به راحتی میتوانیم حساب کنیم. نوآوری: بررسی کنیم که هر بخش دیتاست چقدر پیشنهادهای پرسونالایزدتری میتونه بده.
نوآوری: کلا ما که از کل دیتاست استفاده نمیکنیم برای ریکامند کردن و قراره سمپل بگیریم. پس چه بهتر که بدونیم از کجا سمپل بگیریم که پیشنهادهای بهتری بده. خود اینم یه دستاورده.
دیورسیتی یعنی چقدر آیتمهایی که توی لیست پیشنهادهامون هست با هم فرق دارن. برای این میشه pairwise میزان شباهت آیتمها را با یک معیاری متفاوت از چیزی که برای پیشنهاد دادن استفاده کردیم حساب کنیم و بعد میانگین بگیریم.
نوآوری: ما چون کانتنت یا tag ها را داریم میتوانیم این را استفاده کنیم برای نشان دادن diversity ولی در اینصورت نباید content base پیشنهاد کنیم چون نقض غرض است.
دیورسیفیکیشن از این طریق است که اگر مورد فعلی که میخوای پیشنهاد بدی شبیه موارد قبل است این رو پیشنهاد نده و به جاش یه چیز دیگه بذار یا penalize کن. راه دیگش اینه که چند تا کلاستر داشته باشیم و از هر کلاستر چند تا پیشنهاد بدیم.
نوآوری: میتونیم دیورسیفیکیشن اضافه کنیم به سیستم.
سرندیپیتی یعنی چقدر پیشنهادهای ما سورپرایز کننده هست و برای این یک دیتای بیسلاینی از expected بودن پیشنهادها لازمه تا با اون مقایسه کنیم.
ما اگر همیشه یه سری پیشنهاد خوب تکراری به کاربر بدیم رضایت کاربر به مرور زمان کاهش پیدا میکنه و دیگه برنمیگرده از سیستم استفاده کنه چون همیشه بهش یه سری پیشنهاد تکراری میده. یعنی اول راضیه از پیشنهادها ولی بعد یه مدت حوصلش سر میره.
نوآوری: برای حل این مشکل بیایم زمان rate دادن کاربر به هر آیتم رو هم تو دیتاست در نظر بگیریم. بعد تو تقسیم داده به train و test اول بگیم دادههای یک سال اول رو مثلا split میکنیم و اینجوری که دادهی تهش validation و تست هست و اولش train. چون از دادهی قدیم باید استفاده کنیم برای پیشنهاد دادهی جدید. بعد بیایم همین مدل رو روی دادهی rate های دو سال اول اجرا کنیم و دوباره ارزیابی کنیم. بعد نمودار تغییر نتایج ارزیابی برحسب زمان رو بکشیم. همینطور میتونیم diversity رو اینجوری اندازهگیری کنیم که سیستم در سالهای بعد چه پیشنهادهایی میده که در سالهای قبل نداده بود هیچوقت. سویچ کردن الگوریتم ریکامند کردن در طول زمان باعث افزایش دیورسیتی در طول زمان یا temporal diversity میشه.
نوآوری: میشه یه شبکه یا نتورک ساخت از کتابخانهها و پروژهها اینجوری که اگر دو تا کتابخانه توسط یک پروژه استفاده شدند به هم وصلشان کرد و بعد میزان شباهت دو کتابخانه یعنی طول مسیر بین آندو در گراف حاصل.
توش روشهای online ارزیابی میشه برگشت کاربرها به سیستم ریکامندر، مدتی که بهش نگاه میکنن، ریکامندیشنهایی که take میکنن، آپشنهایی که تغییر میدن و … رو حساب کرد.
نگتیو فیدبکهای ضعیف میشه گرفت تو unaryها برحسب اینکه کاربر چند مورد اول رو skip کرده و مورد دهم رو انتخاب کرده.
در یک سیستم ریکامندر بیمارستانی ما باید به تخصص پزشک هم توجه کنیم. اینکه یه جراحی خیلی محبوبه پس بهت پیشنهادش میکنم کافی نیست. نواوری:سیستم ما هم شبیه همین ریکامندر بیمارستانی هست اینکه صرفا یه کتابخونه محبوبه کافی نیست برای ریکامند کردنش.
نوآوری: تگهای پروژهها را به راحتی میشه از api گیتهاب گرفت.
کورس چهارم اسپشیالیزیشن ریکامندر سیستم: ارزیابی و evaluation
در الگوریتم SVD ما dimension reduction انجام میدهیم که هم دقت را بالا میبرد هم سرعت را. روش کار این است که ماتریس m در n را میشکنیم به ضرب ماتریس m در k و ماتریس k در k و ماتریس k در n. ماتریس اول میشه پروفایل کاربر نسبت به k تا taste مختلف. بعد ماتریس k میشه اینکه هر آیتم چقدر به این k مورد شبیهه. با dot product پروفایل کاربر در میزان نزدیکی آیتم به هر کدام از k مورد عملا میرسیم به امتیاز کاربر به آن آیتم. ولی این کانتنت بیسد نیست چون لزوما این k تا dimension معنیدار نیست و با ریاضی از روی خود ماتریس collaboration به دست میآید. این k را میشود کوچک هم کرد. با این روش ممکن است من شبیه یک user دیگر باشم با اینکه هیچ آیتم مشترکی ندارم چون taste ام شبیه به او است. من سه تا اثر از شکسپیر را دوست دارم و او سه اثر دیگر از شکسپیر را. معمولا ۱۳ تا ۲۰ تا خوبه ولی باید آزمایش کرد. نوآوری: ما هم SVD بزنیم.
نوآوری: FunkSVD و همینطور PLSA هم به کار ما میاد و جذابه. (توضیحات کامل و فرمولهای مربوطه در سه هفتهاول کورس چهارم موجود است.)
هر الگوریتمی نقاط قوت و ضعف خود رو داره. مثلا کلبریتیو فیلترینگ مشکل cold start داره درحالیکه content base نداره ولی content base دیتای مربوط به کانتنت لازم داره که لزوما در دسترس نیست. ترکیب اینا با هم میتونه نقاط ضعف هم رو پوشش بده مثل ماشینی که هم بنزین و هم برق استفاده میکنه و به اونم هایبرید میگن. کلبریتیو فیلترینگ میگه که اگر کاربر این فیلم رو ببینه آیا خوشش میاد؟ پاپیولاریتی میگه آیا کاربر این فیلم رو میبینه؟ بیایم این دو رو ترکیب کنیم. آیا کاربر فیلم رو میبینه و اگر دید آیا خوشش میاد؟
نوآوری: ترکیب پاپیولاریتی و کلبریتیو فیلترینگ معنی میده.
الگوریتمها رو میشه برحسب یه مدل خطی linear ترکیب کرد. یعنی یک ضریبی در امتیازی که از روش اول به دست میاد به علاوه یک ضریبی از امتیازی که از روش دوم به دست میاد و …. نتفیلیکس پرایز به یه الگوریتمی تعلق گرفت که صدها ریکامندر رو ترکیب خطی کرده بود.
بعد خود این ضرایب هم اعداد ثابتی نیستند بلکه یک فانکشنی هستن از آن یوزر یا آیتمی که قراره امتیازش رو پیشبینی کنیم. به این الگوریتم hiearchial linear model میگن. هر الگوریتمی در یک شرایط خاصی ممکنه قوی یا ضعیف باشه. مثلا جایی که داده زیادی دربارهی استفادهی یک کتابخانه یا پروژه داریم میتونیم بریم سراغ کلبریتیو فیلترینگ جاهایی که داده کمی در اینباره داریم بیشتر بریم سراغ روشهای کانتنتبیسد. نوآوری: در ترکیب الگوریتمها ضریب تعداد rate های موجود برای هر آیتم باشه. اگر زیاد بود تاکید بره روی کلبریتیو فیلترینگ اگر کم بود تاکید کم شه و به همون نسبت بره روی کانتنت بیسد.
میشه رنکهای نهایی دو تا الگوریتم رو ترکیب کرد. جایگاه اول رو یک میدیم جایگاه دوم ۰.۸ جایگاه سوم ۰.۶ و جایگاه چهارم ۰.۴ و جایگاه پنجم ۰.۲ (چون ۱ تقسیم بر پنج میشه ۰.۲) بعد میایم امتیاز جایگاه هر آیتمی که توی دو تا رنکینگ داریم رو با هم جمع میزنیم و برحسب حاصل جمع مرتب میکنیم. نوآوری: از این روش هم برای ترکیب الگوریتمها میتونیم استفاده کنیم. فقط در دیتابیس بهتره ترتیب ریکامندیشن ها رو نگه داریم.
میشه با SVD اومد کلبریتیو و کانتنت بیسد رو ترکیب کرد اینجوری که فیچر وکتورها رو از روی میزان شباهت آیتمها به کانتنت هاشون به دست بیاریم.
نوآوری: میشه روش هایبرید کردن اینجوری باشه که اگر همسایههای نزدیکی داشت کلبریتیو کار کنه اگر نداشت کانتنت بیسد یا most popular یعنی به یوزر نگاه کنه و تصمیم بگیره که چه ضریبی بده به هر الگوریتم به جای اینکه به آیتم نگاه کنه.
روش دیگر کلبریتیو فیلترینگ اینه که ما با روش کانتنت بیسد پروفایل ساختیم برای کاربر حالا میایم بر اساس آیتمهایی که به پروفایل کاربر نزدیکن کلبریتیو فیلترینگ اعمال میکنیم.
چند تا ریکامندر داریم که موارد top لیست هر ریکامندر از بقیه بهترن اینجوری که اینا رو هم میشه ترکیب کرد میشه هایبرید کرد. نوآوری: این روش هایبرید کردن برای کار ما واقعا خوبه.
روش دیگر هایبرید سازی اینه که خروجی یک ریکامندر ورودی ریکامندر دیگر را تامین کند. مثلا خروجی ریکامندر کانتنت بیسد میشود پروفایلهایی که برای یوزرها میسازیم. بعد بیایم روی خود این پروفایلها کلبریتیو بزنیم اینجوری که بگیم کی پروفایلش از همه نزدیکتره به شما و آیتمهای او را پیشنهاد خواهم داد. نوآوری: این روش هایبرید کردن همین الان هم تو لیست تسکها هست. شباهت سنجی user_user و content_based
روش دیگر هایبرید کردن از طریق ماتریکس فاکتوریزیشن هست. اینجوری که برای همهی user ها و item ها ما یه سری side information داریم.
ریکامندرهای context-aware یعنی لحاظ کنیم که آیا چیزی که پیشنهاد میدیم به درد این یوزر با situation ای که داره میخوره یا نه. مثالهاش اینه که در نظر بگیره که چه فصلی هست و بر اون اساس برای تعطیلات پیشنهاد بده یا مثلا شلوغ بودن یا آب و هوا یا دمای هوا یا فاصلهی اونجا رو هم لحاظ کنه تو پیشنهادهاش یا رستورانی پیشنهاد کنه که برای بچهها خوب باشه. یا مثلا کاربر مشخص کنه که خوشحاله یا ناراحته و برحسب این کانتکست پیشنهاد موزیک بده یا اینکه داره رانندگی میکنه. نگاه میکنن که هر کانتکست مثلا اینکه شنونده موسیقی خوشحاله چه تاثیری روی rating هاش داره. یعنی کانتکست روی rate ای که کاربر میده تاثیر داره. مثلا اگر یه فیلم بچگانه رو با بچم ببینم احتمالا امتیاز بیشتری بهش میدم تا اینکه تنهایی ببینم. کانتکست میشه شرایط مرتبط با یوزر که تاثیر میذاره روی اینترکشن یوزر با محیط.
ما rating هایی که مربوط به کانتکست هستن رو filter میکنیم و بعد الگوریتم ریکامندیشن رو استفاده میکنیم. چون pre-filter کردیم بقیه کانتکستها رو میشه گفت که context-aware هست. اشکالش اینه که دیتاست رو sparse تر میکنه این روش. روش دوم اینه که ریکامندیشنهایی که به کانتکست کاربر مربوطه رو post-filter کنیم و بهش پیشنهاد بدیم. روش سوم اینه که کانتکست رو در مرحلهی learn کردن در نظر بگیریم. یعنی به جای ماتریس یوزر و rate بیایم ماتریس سه بعدی یوزر و rate و کانتکست رو بسازیم. یه روش دیگه اینه که یوزر رو توی هر کانتکست یه یوزر جدید حساب کنیم. ممکنه کانتکست خودش dynamic باشه در اینصورت باید یک روش active learning استفاده کنیم. یک روش مدلسازی میزان deviation ریتینگ کاربرها در حالت general که کانتکست رو در نظر نگیریم با حالتی که در نظر بگیریم هست.
کاری که اسپاتیفای کرده اینه که کاربر ها رو به چند تا باکت تقسیم کرده. افرادی که هاردکور آهنگ گوش میدن یا مثلا دنبال چیزای جدیدن ولی نه چیزای خیلی متفاوتی از اونایی که میشناسن یا کاربرهایی که سلیقه مشخص خاصی اصلا ندارن و همه چیو گوش میدن یا افرادی که رادیو استیشن گوش میدن و … و برای هر کدوم از یه مدلی استفاده میکنن. نوآوری: ما هم میتونیم ریپازیتوری ها رو به چند باکت تقسیم کنیم و برای هر باکت از یه الگوریتمی استفاده کنیم.